こんにちは、株式会社 ACES (以下 ACES) の檜口です。普段はアルゴリズムエンジニアとして Deep Learning (以下 deep) を中心とする研究開発業務に従事しています。
ACES ではリアルな現場の画像認識を行う機会が多いです。この時さまざまなアルゴリズムを利用していますが、その中でもトラッキング技術は多くのアルゴリズムの基礎となるモジュールとして重要です。例えば、複数の人物がいるような状況で、ある人物に着目してなんらかの分析を行いたいときなどにはトラッキング技術が必須になってきます。
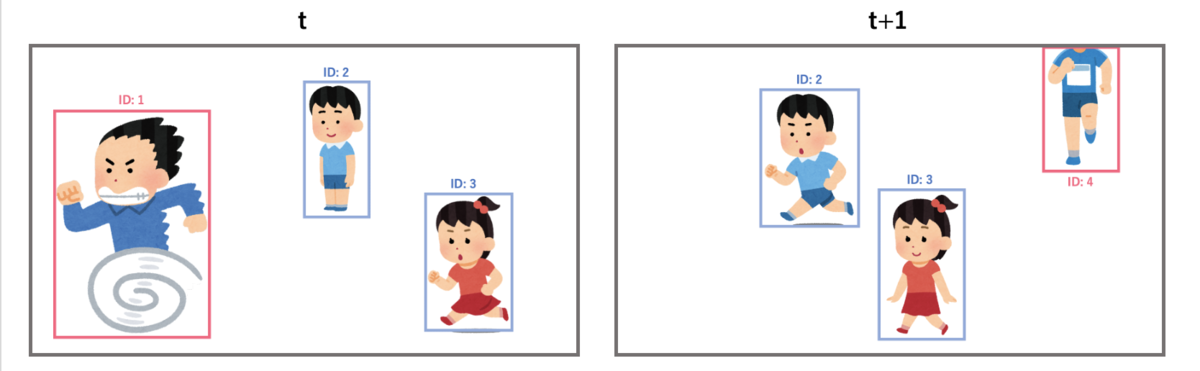
トラッキング技術は研究領域では multiple-object tracking (MOT) と呼ばれており1、動画とオブジェクトのクラスが与えられたときに、動画中の対象のオブジェクトの位置を特定しつつ、個別のオブジェクトがどのように移動したかを追跡するタスクです。Machine learning の文脈でより正確に記述するならば MOT は動画中のオブジェクト位置を bbox2 で検出しつつ (物体検出、object detection) 、同一のオブジェクトが動画中で検出された時には、それらが同一の ID を持つようにする (フレーム間でのオブジェクトの紐付け、association) というタスクになっています。
MOT は deep model を使った物体検出モデルがパフォーマンスを伸ばすにしたがって、物体検出モデルの出力を利用してトラッキングを行う tracking-by-detection というパラダイムで大きく性能を向上させました。Tracking-by-detection 方式を採用した MOT アルゴリズムは2016年以降、現在まで state-of-the-art であり続けており、その動向からは目が離せません。
このポストでは tracking-by-detection 方式の MOT における基本的なアプローチを解説したのち、アルゴリズム発展の歴史を紹介したいと思います。MOT アルゴリズム発展の軸としては以下のようなものがあると思います。
- (2016年) 物体検出を deep で置き換え、association はカルマンフィルタを基にした affinity matrix を介して行う
- (2016年〜2017年) Deep model で抽出した特徴量をベースにして類似度を計算して affinity matrix を利用する
- (2019年〜現在) 一体型モデルの学習難易度を下げる
- (2021年〜現在) コサイン類似度に変わる類似度を利用する
- (2020年〜現在) Transformer の導入
今回紹介するのは上記研究の発展軸のうち前半二つです。
MOT のキモ 、association
Tracking-by-detection パラダイムに従う場合、物体検出を独立したタスクとして切り離して考えると、MOT の本質はフレーム間のオブジェクトの紐付け、すなわち association にあることがわかります。このセクションでは具体的な研究の紹介に移る前に MOT のキモである association について解説します。
MOT3 では t-1 フレーム目までのオブジェクトの追跡情報 (tracklet) と t フレーム目での物体検出の結果 (detection) を逐次的に紐づける必要があります。このような紐付けを動画の最初のフレームから最後のフレームまで連続して行うと、動画全体のオブジェクトのトラッキングができるようになります。
紐付けに際して tracklet と detection は似ているはずであるという仮定を導入します。つまり、似ている tracklet と detection をフレームごとに繋いでいって、最終的に動画全体でのオブジェクトの軌跡を得ることを考えます。この時の『似ている』とは以下のような状態を指します。
- 検出された bbox と tracklet から予測された bbox の位置が近い
- 検出された bbox と tracklet から予測された bbox の形状が似ている
- 検出された bbox の中と以前 tracklet に紐づけられた bbox の中の視覚的な特徴が似ている
この仮定は動画のフレームレートが十分高ければ尤もらしい仮定だと思います。実装上は 1、2の tracklet からの bbox の予測はカルマンフィルタ4を、3の視覚的な類似度は deep model によって抽出された特徴ベクトルを利用することによって達成されます。
さて、上記のような tracklet と detection の類似度が計算できたとすると、その類似度の和が最大になるような組み合わせを計算すれば最適な紐付けが決められそうです。そのような目的を達成できるアルゴリズムとしてはハンガリアンアルゴリズムという割り当てアルゴリズムが知られており5、MOT アルゴリズムで広く活用されています。ハンガリアンアルゴリズムの概要は英語版 Wikipedia に記述が見つかります。なお、ハンガリアンアルゴリズムは scipy.optimize.linear_sum_assignment などから利用できるので、自前で実装する必要はありません。
さて、物体検出を所与のものとして、さらにハンガリアンアルゴリズムを割り当てアルゴリズムとして採用することを決めてしまうと、MOT というタスクはハンガリアンアルゴリズムに供する affinity matrix (tracklet と detection の類似度を並べた行列)6 を作るタスクであると言い換えることができます。実際、近年発展した MOT アルゴリズムのほとんどがこの affinity matrix をいかにうまく作るかにフォーカスして研究が行われています。
MOT の代表的なアルゴリズム
2.1. SORT
ポイント:物体検出を deep で置き換え、association はカルマンフィルタを基にした affinity matrix を介して行う
物体検出を行う deep model で一番有名なのは何かというのには議論もあるかと思いますが、個人的には Faster R-CNN かなと思っています。この辺りで deep による物体検出の基礎は概ね確立されたように思います。Faster R-CNN が公開されたのは2015年のことですが、このような物体検出モデルの目覚ましい発展を受けて2016年に公開されたのが SORT です。SORT は物体検出モデルからトラッキングのターゲットとなる bbox の情報を受け取り、それら bbox を直前フレームまでの情報からカルマンフィルタによって予測された bbox と紐付けます。このとき、affinity matrix はカルマンフィルタによって予測された tracklet の bbox と検出された bbox の IoU7 を使います。
SORT の優れた点はとにかく高速に動作することで、計算時間は ①物体検出モデルの推論時間 ②カルマンフィルタの予測 ③affinity matrix の計算 (= IoU の計算) ④ハンガリアンアルゴリズム にかかる時間程度です。これらの計算は ① を除いて全て非 deep であり、物体検出さえ動作すれば紐付け自体は CPU 上でも高速で動作します。また、物体検出のモデルのパフォーマンスが高ければ高いほど SORT は非常に高いパフォーマンスを発揮します。実際、MOT のベンチマークで正解の bbox を使って SORT を動作させると (系列にもよりますが) ほぼ100%に近いパフォーマンスが出て驚いた記憶があります。
逆に SORT の欠点はオクルージョン (オブジェクトが物体の陰に隠れること) やオブジェクト同士の交錯などに弱いことが知られています。association の際に bbox の位置情報しか見ていないので、物陰に一時的に消えたオブジェクトが再び画面に戻ってきたときなどにオブジェクトがカルマンフィルタで予測できる位置に現れてくれないと tracklet が途切れてしまったり、オブジェクトが交錯したときに ID switch (ふたつのオブジェクトの ID が入れ替わってしまうこと) が起きることを避けることができません。
2.2. DeepSORT
ポイント:Deep model で抽出した特徴量をベースにして類似度を計算して affinity matrix を利用する
SORT の欠点はオブジェクトの位置しか見ていないことに由来していたので、位置だけではなく視覚的な特徴量 (appearance feature / visual feature) も考慮すればもっとパフォーマンスが出るのではないか?という仮説の元に研究が進みました。こうして登場したのが DeepSORT です8。DeepSORT は SORT の著者らが発表したモデルで、その名の通り deep な特徴量を使って association を行います。
DeepSORT では物体検出モデルによって検出された bbox 領域に対して person-ReID9 データセットで学習されたモデル10を適用して特徴ベクトルを獲得します。person-ReID モデルによって抽出された特徴量は tracklet の持つ特徴量とのコサイン類似度を affinity matrix として association に利用します。ハンガリアンアルゴリズムによって紐付けが発生した tracklet にはその時紐づいた detection の特徴量が登録されます。Association の際には Matching Cascade と呼ばれるアルゴリズムを採用しており、直近で観測があった tracklet に優先的に association を行うようなアルゴリズムを採用しています。
移動制約には SORT に引き続きカルマンフィルタを利用していますが、カルマンフィルタで推定する bbox の状態が変更されていたり、カルマンフィルタによって予測された bbox と検出された bbox の類似度が IoU からカルマンフィルタの推定の不確実さを利用したものに置き換えられたりなどのマイナーチェンジがいくつか施されています。DeepSORT で提案されたカルマンフィルタはこれ以降のカルマンフィルタを用いたほとんどのアルゴリズムに利用されており、MOT におけるカルマンフィルタの利用方法のデファクトを作ったという意味で重要性が高いと思います。
DeepSORT の利点は高速に動作することとオクルージョンに強いことが挙げられます。SORT よりは速度は落ちるものの視覚的な特徴量を紐付けに利用するようにしたことでオクルージョンによって多少の期間観測がなされなかったとしても、再度観測ができた時に紐付けができるようになりました。
DeepSORT の欠点は物体検出モデルによって検出されたオブジェクトを ReID モデルにかけるため、モデル2回分の推論が必要で推論時間がかかることや、検出された bbox を固定サイズにリサイズして特徴抽出を行うため、オブジェクトのサイズを視覚特徴量に反映できない11こと、オブジェクト周辺の文脈を考慮できないことなどがあると思います。また、オブジェクトの移動には引き続きカルマンフィルタを採用しているため、カルマンフィルタの仮定に反するような動きをするオブジェクトは tracklet が切れてしまうことがあります。
まとめ
今回の記事では MOT アルゴリズムで標準的に利用されている association の仕組みとそれ以降の MOT 研究のベースとなるような二つのアルゴリズム (SORT/DeepSORT) について紹介しました。次回記事では DeepSORT 以後に登場したアルゴリズムの紹介をしていきたいと思います。
ACESでは積極的に採用を行っています!
ACESでは、積極的に採用を行っています。ACESでは「アルゴリズムで、社会をもっとシンプルに」するために様々な観点からアルゴリズムの開発を行っています。ACESに興味を持っていただいた方がいらっしゃいましたら、お気軽にご連絡下さい!
会社紹介資料はこちら↓
ACESのリクルートページはこちら↓
-
トラッキングのタスクとしては single object tracking (SOT) や pose tracking などもありますが、この記事では MOT にフォーカスしています。↩
-
bbox は bounding box の略で、画像中のオブジェクトの位置を長方形で囲った領域として表現したものです。↩
-
ここではオンラインで動作する MOT を仮定しています。なお、近年提案されているアルゴリズムのほとんどはオンラインでの動作を仮定しています。↩
-
MOT で使われるのは専ら線形カルマンフィルタで、これはオブジェクトの動きに等速直線運動を仮定しています。実際、動画のフレームレートが十分に高ければ、オブジェクトの動きは等速直線運動で近似できそうなので、実用上はうまくいくことが多いです。しかしながら、突然進行方向を切り返すなどの動きをするとうまく動きを予測することができない場合があります。あるいは長期間のオクルージョンが発生した場合にはオブジェクトの動きに等速直線運動を仮定するとうまく動きが予測できない場合があります。そのような場合には本来紐付けられるはずだった tracklet と detection が紐づけられなくなり、MOT アルゴリズムのパフォーマンスが下がってしまうことが問題点として指摘されています。↩
-
実際には類似度に
-1をかけたコストを考えて、コスト合計が最小になるような組み合わせをハンガリアンアルゴリズムで計算します。↩ -
あるいは cost matrix についての研究と言い換えることもできます。Cost matrix は tracklet と detection の類似度の代わりに距離を表現した行列です。こちらの用語も MOT 研究では頻繁に使われます。↩
-
IoU は intersection over union の略で bbox 同士の重なり度合い (近さ) の指標として使われます。↩
-
DeepSORT は appearance feature を使ったアルゴリズムの初出ではありません。ここでは SORT との差分がわかりやすかったため採用しました。DeepSORT 以前の appearance feature を使うモデルとしては POI が比較的有名だと思います。DeepSORT でも POI の著者が公開している detection の結果をアルゴリズム評価のために利用しています。↩
-
Person ReID は与えられた人物 (クエリ) が同一人物かどうかを判定したり、与えられた人物が事前に登録された人物 (ギャラリー) の誰に当たるのかを判定するタスクです。顔認証と類似していますが、一般に顔認証が高解像度の顔にフォーカスした画像を利用するのに対して、person ReID は監視カメラなどの画質の粗い画像でなどから得られる全身の画像がクエリとして与えられることなどが違いとして挙げられます。↩
-
他の特徴量ベースのモデルでもほぼ共通ですが、person-ReID では ResNet-base のネットワークアーキテクチャが使われることが多く、特殊なアーキテクチャはあまり使われない印象です。リアルタイムでのトラッキングを目指すときには特徴抽出は可能な限り高速で動作した方が良いので、あまり複雑なネットワークアーキテクチャは使われづらいという背景があるかもしれないです。↩
-
解像度の違いなどによって実質的にサイズが考慮されている可能性はあります。↩