Microsoft Teams (以下Teams) やMicrosoftOutlook (以下Outlook) は日本国内で見ても利用率が高く、ACES MeetとしてもTeamsを利用するユーザーもACES Meetの機能を利用できるようになることや、Outlookを利用しているユーザーがよりACES Meetを使いやすくなることは今後サービスを多くの方にご利用いただくには必要不可欠となっていました。
昨年末のChatGPTのリリース以降、大規模言語モデル(large language model, LLM)の社会実装が急速に進んできています。弊社でも商談解析AIツールACES MeetにLLMを組み込むなど、LLMの活用を広げています。こちらに関してはLLMを活用したAIまとめ機能リリースの裏側について過去記事を書いてありますのでご興味ある方はぜひご覧ください。
商談の特徴として、必ずその場に買い手と売り手が存在していることが挙げられます。
そこで、ただ単に文字起こしの内容だけを ChatGPT API に渡すのではなく、話者名もセットで渡し、更に誰が売り手で誰が買い手かという情報を与えることで、 ChatGPT API に買い手側の発言が重要度が高く、買い手側の発言を中心に要約してもらうようなプロンプトを用意しました。
結果として、「まとめ」と「商談ヒアリング項目(BANTC)」については全ての会話文を渡した方が意味のある要約が出力される傾向があることが分かり、「ネクストアクション」については、商談の前半を思い切ってカットすることで、ネクストアクションとして違和感のある項目が減少する傾向が掴めたため、 ChatGPT API に渡す前にあえてデータをカットして渡すようにする工夫を入れています。
検証4: 出力形式の検証
ソフトウェア上で ChatGPT API からの出力結果をハンドリングしやすくするために、どの出力形式がベストかについての検証も行いました。
そこで、質問に関連する一部の文書だけを検索してきて prompt に追加することが1つの解決策になります。
このように言語モデルの知識を補完するために関連する文書を外部の文書集合から検索してきて言語モデルに入力として与えるような技術を、Retrieval-augmented Language Model (LM) と言います。(新しい Bing AI チャットは Web からの検索で知識を補うようなことをしていますね。参照1,2)
Open AI からも検索に使える embedding という API が公開されており、手軽に検索機能を実装するにはそれで十分かもしれません。(参照)しかし、その API は有料であることに加えて、embedding の訓練に使われたデータとは異なるような特殊なドメインの文書が検索対象で、一般的にメジャーではない語彙が多い場合には Open AI の embedding では検索の精度が劣化してしまう可能性もあります。
公式の Documentation でも、embedding は2020年8月までのデータを用いて訓練されたため、それ以降に起きたイベントについての知識には弱いことが欠点として挙げられています。(参照)
例えば、ACESが提供する "ACES Meet" は "AIがオンライン商談の録画・書き起こしを行い、商談の内容や温度感を共有・解析できる営業支援AIツール"(参照)なのですが、実際に OpenAI の embedding (text-embedding-ada-002)で計算したcos類似度は以下のようでした。
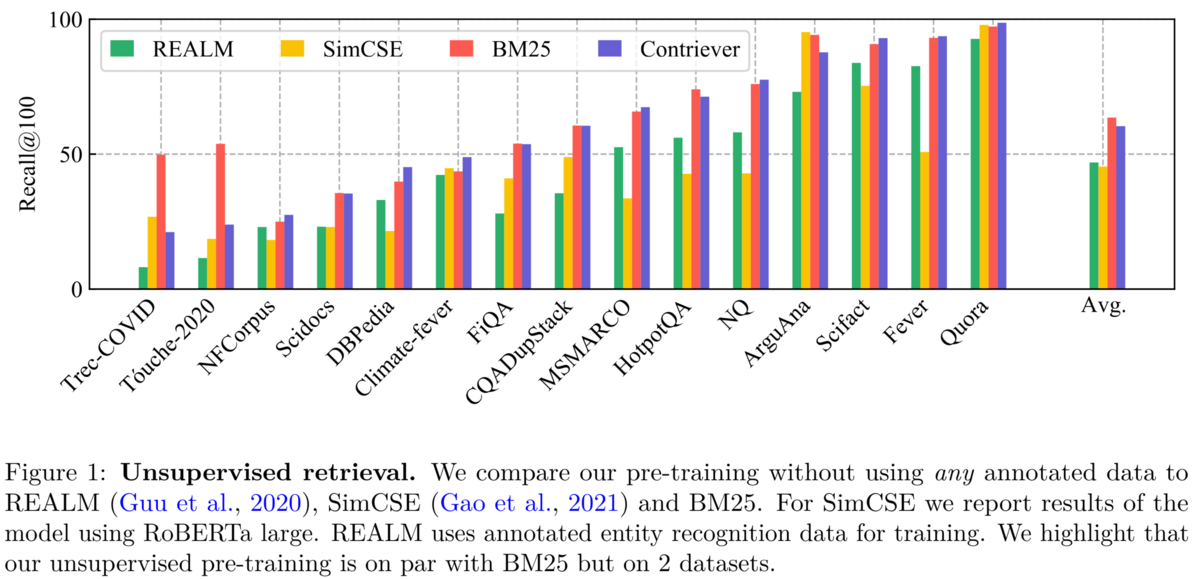
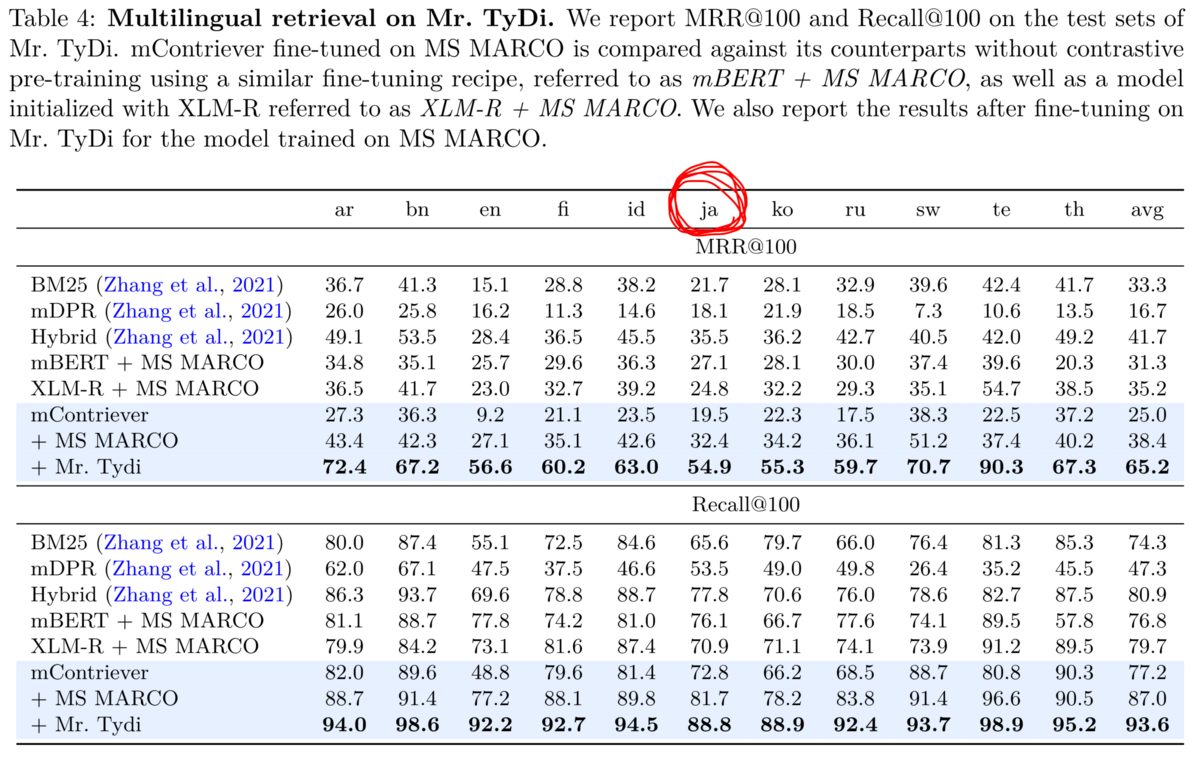
(日本語含む)29の言語のデータで訓練したmContrieverは日本語データ (ja) に対してもある程度汎化可能です。
学習用のコードと学習済みモデルは公開されています。
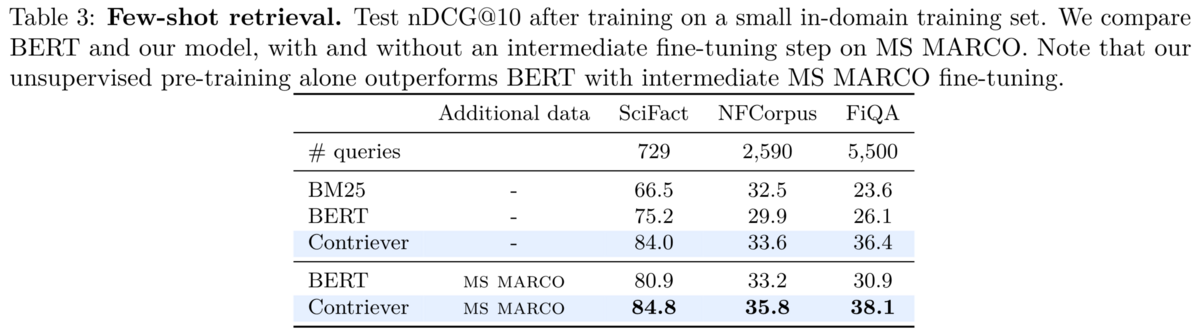
mContriever を MS MARCO でfine-tuneしたモデルはこちらのレポジトリと以下のコードで簡単に使えます。
from src.contriever import Contriever
mcontriever_msmarco = Contriever.from_pretrained("facebook/mcontriever-msmarco")
LLMと一緒にRetrieverを使う
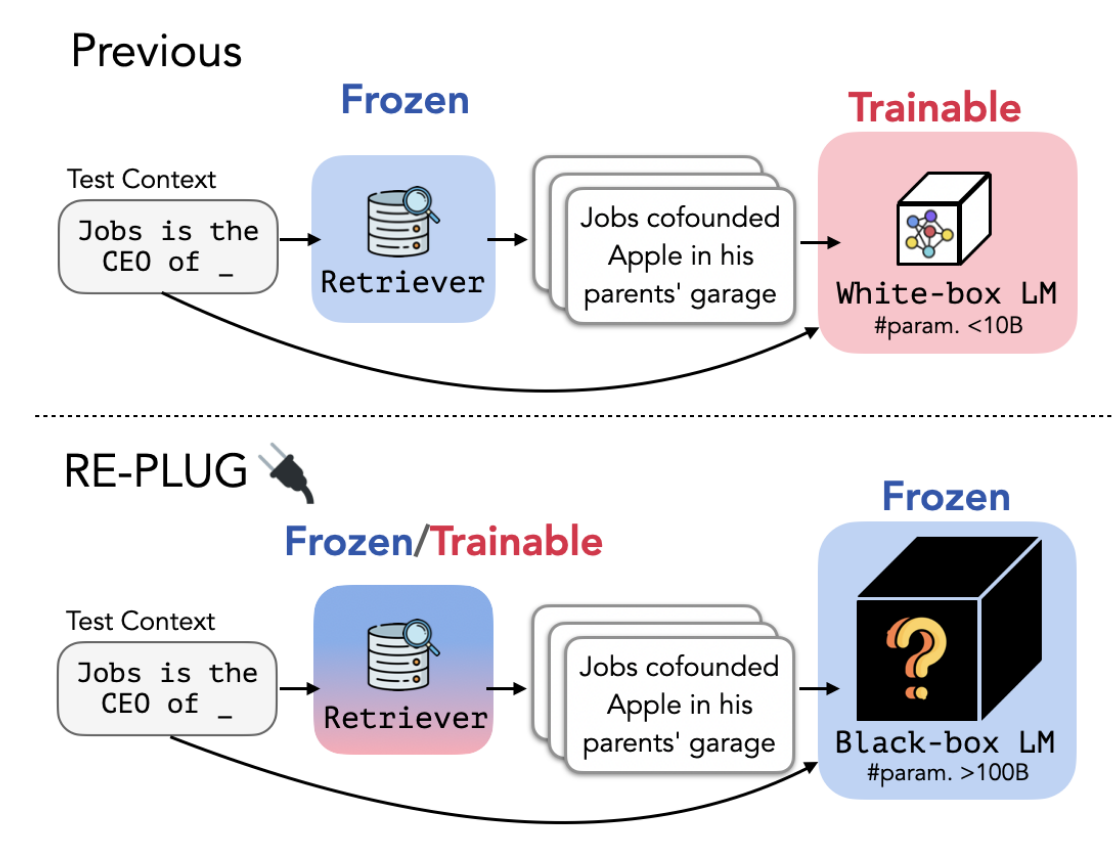
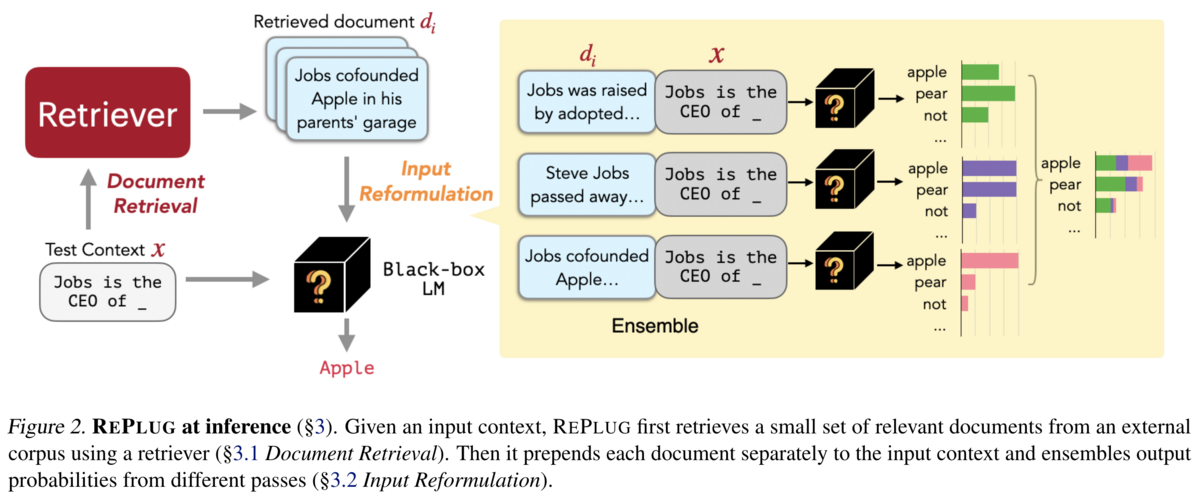
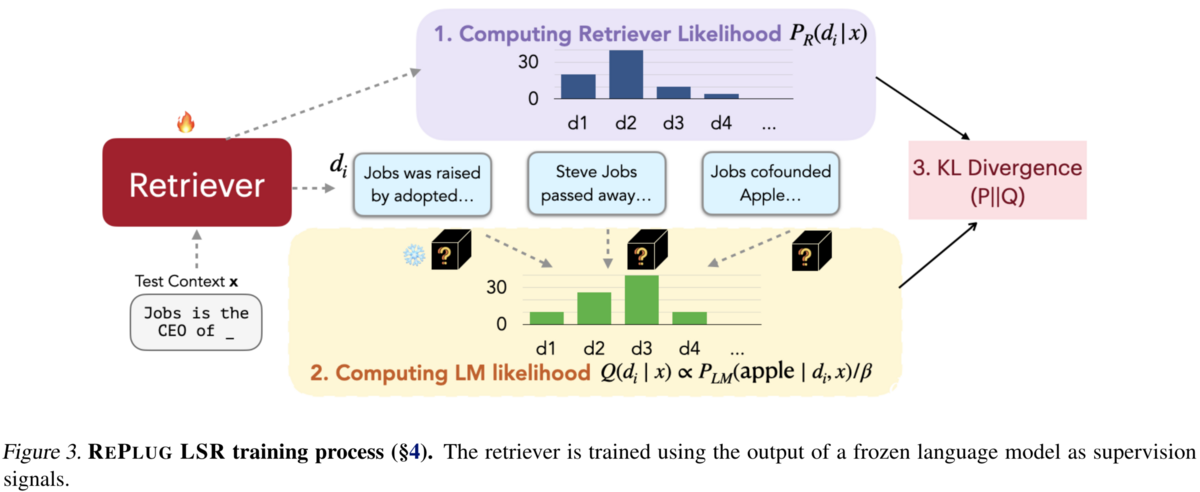
REPLUG: Retrieval-Augmented Black-Box Language Models (Shi+ 2023)
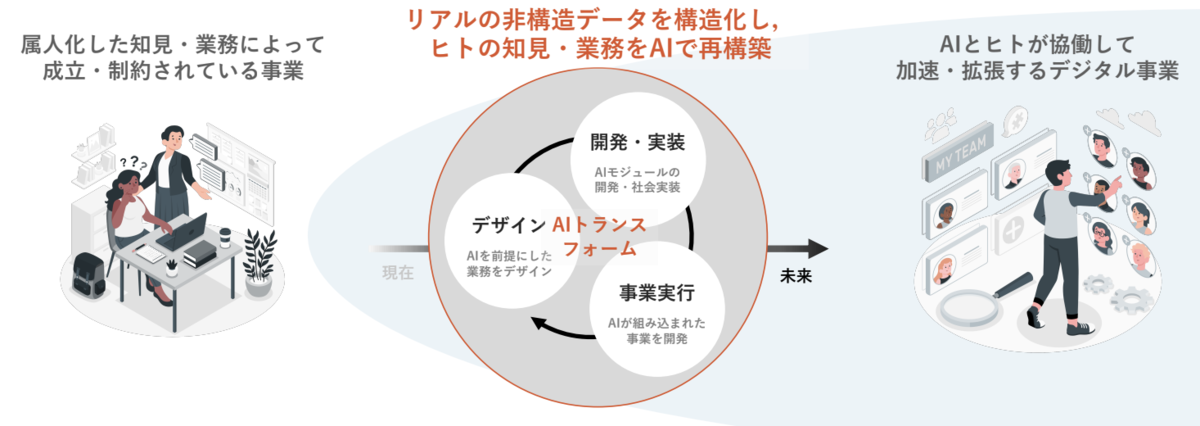
また、人とAIが協働する中で、① データが蓄積され、AIが強くなること、② より質の高いAIのサポートを受けることで人も強くなること、③ 質の高いデータがAIにFBされること、のループを回すことによって、人とAIが共に進化することを目指します。このような、人間がシステムのループの中で相互作用を生み出すことは Human in the loopと呼ばれており、人とAIの不得意をそれぞれが補う形で協働することをイメージしています。
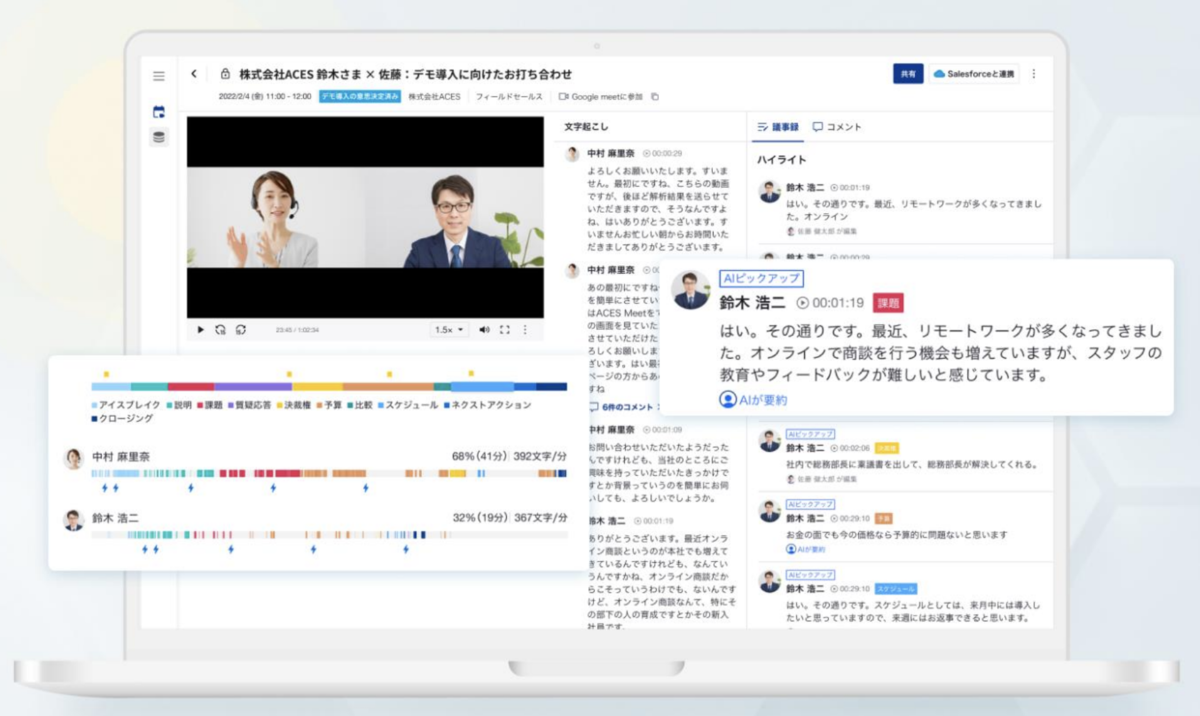
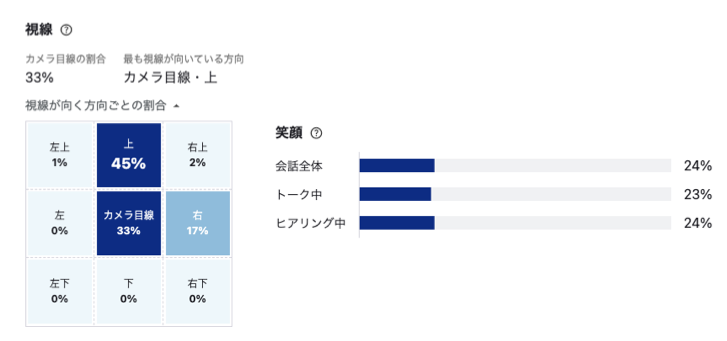
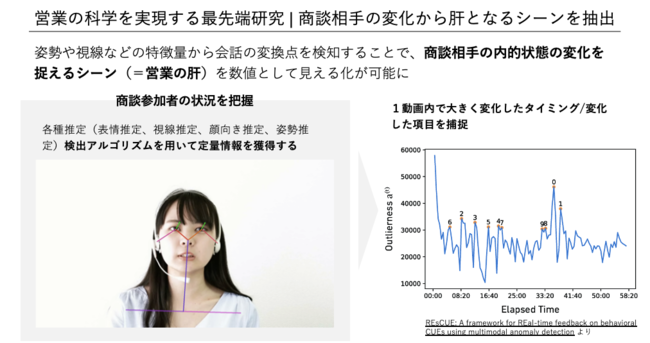
現在ACES Meetに搭載されているアルゴリズムは内部で開発されているもののうち一部のみで、今後も内容の拡充が行われる予定です。内部的には他社との取り組みを含めて、様々な研究・開発が行われているところです。例えば、人材アセスメント支援業務におけるプロジェクトとして以下のような研究を行い、CHI 2022のワークショップである Trust and Reliance in Human-AI Teaming に採択されています。