こんにちは、株式会社 ACES (以下 ACES) の檜口です。普段はアルゴリズムエンジニアとして Deep Learning (以下 deep) を中心とする研究開発業務に従事しています。
このポストは multiple object tracking (MOT) の解説と簡単なアルゴリズム紹介をした前回ポストの続きで、引き続き現代 MOT のアルゴリズム紹介を行います。前回記事で紹介したキーワードの説明は省略されているため、適宜前回記事を見返していただければと思います。
- (2016年) 物体検出を deep で置き換え、association はカルマンフィルタを基にした affinity matrix を介して行う
- (2016年〜2017年) Deep model で抽出した特徴量をベースにして類似度を計算して affinity matrix を利用する
- (2019年〜現在) 一体型モデルの導入
- ex. JDE, FairMOT
- (2021年〜現在) 類似度計算の改善
- ex. UniTrack
- (2020年〜現在) Transformer の導入
- ex. TransMOT
- (2021年〜現在) カルマンフィルタモデルの拡張
- ex. ByteTrack
今回紹介するのは上記研究の発展軸のうち後半四つです。(最後の一つは前回ポストにはない項目ですが、新たに付け加えました。)
MOT の代表的なアルゴリズム
1. 一体型モデルの導入
MOT モデルは物体検出とオブジェクトの特徴抽出を別々の deep モデルを用いて行う分離型と、物体検出とオブジェクトの特徴抽出を単一の deep model で行う一体型が存在します。分離型は訓練の容易さやアルゴリズムの保守性が売りですが、二つの deep モデルを直列に利用する関係でどうしても推論速度が遅くなりがちです。一体型モデルは訓練は難しくなるものの、単一の deep model で推論を完結させられるため、速度面で優れています。また、オブジェクトの周辺の文脈を特徴量に反映できる (と期待される) ため1、うまく学習できた際には分離型のモデルより高いパフォーマンスを発揮することができます。
1.1. JDE
ポイント:一体型モデルの学習難易度を下げる
一体型のマイルストーンの一つは2019年に提案された JDE だと思います2。このモデルは本ポスト執筆時点で papers with code の MOT ベンチマーク で9位に位置しています。
JDE はマルチタスク学習の各ロスの係数を自動調整する機構を導入して物体検出と特徴抽出の学習を一つのネットワークで行う際のハードルを下げたことが貢献として大きいと思います。なお、この機構は MOT に限らずマルチタスク学習の文脈で広く使えるもので、元々はセグメンテーションや深度推定などのマルチタスク学習を行うために提案されたようです。
また、tracklet の appearance feature を移動平均で保持していることも特徴です。過去のモメンタム項を重ために持たせた appearance feature は交錯などの直近フレームでの摂動に対して強くなるので、ID switch をかなり抑制することができます。
1.2. FairMOT
ポイント:一体型モデルの物体検出タスクと特徴抽出タスクのバランスを適正化する
FairMOT は2020年に提案された一体型のモデルで、JDE の強化版3という表現がしっくりきます。マルチタスク学習の係数自動調整機能などを引き継いだ上で、マルチタスク学習における物体検出と特徴抽出の学習の不均衡を改善する (二つの学習を fair にする) 工夫が数多く組み込まれています。YOLOv4 のようにベストプラクティスの集大成といった感じの研究です。このモデルは本ポスト執筆時点で papers with code の MOT ベンチマーク で2位に位置しています。
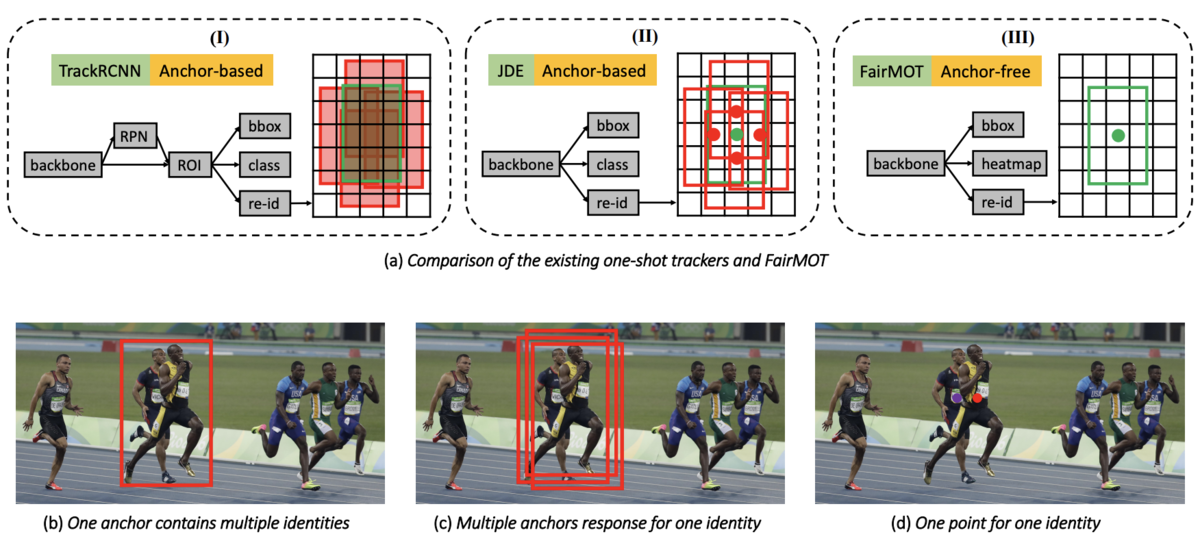
FairMOT の JDE に対する差分として大きいものは、anchor-based のネットワークではなく、anchor-free のネットワークを採用したことです4。具体的には FairMOT では CenterNet を学習のパラダイムとして採用しています。anchor-based のモデルは一つの anchor に複数の target が紐づいてしまう && 一つの target に対して複数の anchor が紐づいてしまい、これが特徴抽出の学習を進める上で障害になることなどが指摘されています。実際、ablation study では anchor-based のモデルより anchor-free のモデルの方が高いパフォーマンスが出ています。また、オブジェクトの特徴量の次元を減らすことでも物体検出と特徴抽出の学習の不均衡を改善できたことが報告されています5。
2. 類似度計算の改善
MOT において視覚的な特徴量を deep model によって抽出して紐付けに利用する際には、コサイン類似度を利用するのが主流です。実際、今までに紹介した DeepSORT や JDE 、FairMOT はいずれもコサイン類似度を利用して紐付けを行なっています。ところで、オブジェクト同士の類似度が測れるのであれば、類似度の指標は必ずしもコサイン類似度である必要はありません。UniTrack は紐付けに利用できる類似度はコサイン類似度だけではないことを示した論文として価値が高いと思います。
2.1. UniTrack
ポイント:コサイン類似度に変わる類似度を利用する
UniTrack はトラッキングタスク (SOT, MOT, PoseTrack 等) に共通した特徴抽出器は作れないか?という問いの元に提案された手法です。結論から言えば、トラッキングに使う特徴抽出器は ReID や MOT のデータセットで学習する必要は必ずしもなく、大規模データセットで pretrain した教師あり or 自己教師あり学習済みモデルであればよいということが主張されています。このモデルは本ポスト執筆時点で papers with code の MOT ベンチマーク で3位に位置しています。
UniTrack はトラッキングにおける特徴抽出器のチョイスの幅を広げたという点がメインの主張ではありますが、それ以外にもコサイン類似度に代わる、Reconstruction Similarity Metric (RSM) と呼ばれる新しい affinity matrix の提案がなされている点は注目に値します。RSM はデータセットにもよりますが概ねコサイン類似度よりもパフォーマンスが高く、既存のモデルにも比較的簡単に組み込めるので、個人的にはかなりのブレイクスルーだと思っています。今後は UniTrack の成功を受けてコサイン類似度に代わるパフォーマンスの高い affinity matrix 計算方法に関する提案が増えることを期待しています。
3. Transformer の導入
3.1. TransMOT
ポイント:オブジェクトの紐付けに transformer を利用する
TransMOT はオブジェクトの移動制約を transformer によってモデリングしたアルゴリズムで、物体の移動を data driven に学習することができます。このモデルは本ポスト執筆時点で papers with code の MOT ベンチマーク で1位に位置していますが、残念なことに実装は公開されていません。カルマンフィルタを使わずこのベンチマークのトップを取っているモデルは自分が MOT を追い始めてから初めてだと思います6。
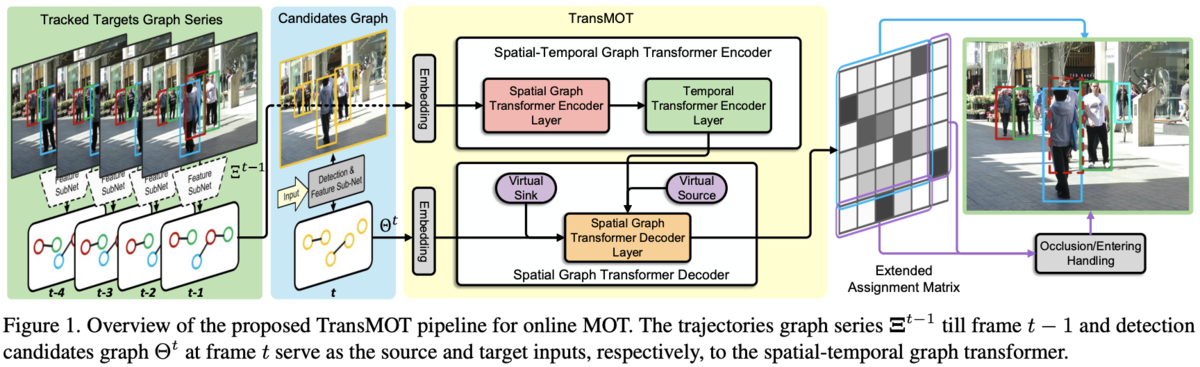
既存の多くのアルゴリズムが cost matrix を経由して association を作成していたのに対して、TransMOT は過去のフレームの情報と現在のフレームの情報を入力にして association matrix7 を直接出力します。より具体的には、TransMOT は検出されたオブジェクト間の関係性を「オブジェクト同士の IoU が非零であればフラグが立つような隣接行列」と「オブジェクト同士の IoU を格納したオブジェクト間ノードの重み行列」で表現したものと検出されたオブジェクトの特徴量を入力として、Spatial Graph Transformer Encoder / Temporal Transformer Encoder / Spatial Graph Transformer Decoder の3つの encoder / decoder を用いて association matrix を出力します。それぞれの encoder / decoder は次のような働きを持ちます。
- Spatial Graph Transformer Encoder: それぞれのフレームで独立に空間的な情報をエンコードします。空間的な情報とはオブジェクト間の位置関係を記述した隣接行列と重み行列です。
- Temporal Transformer Encoder: フレーム間の時系列的な情報をエンコードします。Spatial Graph Transformer Encoder で encode した各フレームの情報を統合する役割を持ちます。
- Spatial Graph Transformer Decoder: 上記2つの encoder を通して得られた情報をデコードして association matrix を出力します。
TransMOT の優れた点はカルマンフィルタなどのヒューリスティクスに頼っていた物体の動きやオブジェクト間相互作用を deep model に押し込めて高いパフォーマンスを保ちつつ学習可能にしたことです。今までも物体の動きを deep model でモデリングするような提案はいくつかされていましたが、カルマンフィルタ+ハンガリアンアルゴリズムタイプのアルゴリズムを超えるようなものはありませんでした。コードが公開されていないのは残念ですが、もし公開されたら TransMOT のようなアプローチのモデルがどんどん update されていくような気がします。
4. カルマンフィルタモデルの拡張
4.1. ByteTrack
ポイント:deep 特徴量をベースにしたマッチングを廃してカルマンフィルタのみを使って高速に予測する
ByteTrack は FPS を向上させるために deep 特徴量を使わず、カルマンフィルタによる移動予測だけでトラッキングを行います。このモデルは MOT17 のリーダーズボードにおいて執筆時点で1位を獲得しています。ByteTrack の名前の由来は tracking BY associaTing Every detection box instead of only the high score ones の略とのことですが、これはおそらくこじつけで、ByteDance が開発したからこの名称がついていると思われます。
一般的なトラッキングアルゴリズムが confidence の低いオブジェクトをトラッキング対象から外して紐付けを行うのに対して、ByteTrack は confidence の高いオブジェクトを紐付けを先に行い、その後 confidence の低いオブジェクトの紐付けを行う2段階の紐付け8を提案しています。Deep 特徴量を使っていない+カルマンフィルタでオブジェクトの移動予測と紐付けを行うことから、ByteTrack は前回記事で紹介した SORT の紐付けを2回行うように改良したアルゴリズムと捉えることができそうです。実際論文中でも SORT や DeepSORT との比較が行われています。
カルマンフィルタを使うトラッキングアルゴリズムは物体検出の精度が重要になってくるため、論文中では物体検出器のチョイスに紙面が多めに割かれています。ByteBrack は物体検出器に COCO で pretrain された yolov5x を使い、人物オブジェクトを多く含むデータセット (MOT17/CrowdHuman/CityPerson/ETHZ) で finetune しています。物体検出器が強力ならカルマンフィルタだけでもトラッキングができるというのは SORT の時代 (2016年ごろ) から主張されていましたが、ここまで高いパフォーマンスを発揮できるのは驚きでした。
まとめ
今回の記事では現代的な MOT アルゴリズムの紹介を行いました。今回紹介した研究は比較的開拓されたばかりでこれからも発展のしがいがあるような領域だと思います。個人的にはコサイン類似度以外の類似度を採用した UniTrack や類似度を implicit に表現した TransMOT は非常に面白い研究だと思います。MOT アルゴリズムを実運用に移していくとなると、オクルージョン等で必ずしもオブジェクトが常に見えているわけではないので、やはり ByteTrack のようなオブジェクトの視覚的情報を一切使わないモデルはちょっと厳しくて、類似度をうまく表現していくことが大切であるように感じます。今後もこの方面の研究が進むことを期待しています。
ACESでは積極的に採用を行っています!
ACESでは、積極的に採用を行っています。ACESでは「アルゴリズムで、社会をもっとシンプルに」するために様々な観点からアルゴリズムの開発を行っています。ACESに興味を持っていただいた方がいらっしゃいましたら、お気軽にご連絡下さい!
会社紹介資料はこちら↓
ACESのリクルートページはこちら↓
-
分離型のモデルはオブジェクトを含む bounding box を入力として特徴抽出をするため、オブジェクトの周囲の文脈を特徴に反映させることができません。↩
-
JDE は一体型モデルを初めて提案したわけではないですが、マルチタスク学習の係数自動調整機能などのちのアルゴリズム (FairMOT) につながる提案をしているためピックアップしました。↩
-
実装を眺めると FairMOT のコードの大半が JDE から移植されています。↩
-
Anchor-based とは物体検出モデルを学習する際に、特定の畳み込みカーネルに特定のサイズの target の予測を担当させるような仕組みを指します。大抵の物体検出モデルは anchor-based であり、例えば Faster-RCNN や EfficientDet 、yolo シリーズ (yolox を除く) などは anchor-based です。一方、anchor-free とは物体検出モデルを学習する際に anchor-based のように特定のカーネルと target を紐づけることなく、一つの畳み込みカーネルで全ての予測をさせるようなモデルを指します。Anchor-free モデルの代表例は CenterNet です。↩
-
MOT のメトリクス全てにおいて特徴次元が低次元の方が良いというわけではないことには注意が必要です。ただ、低次元の方が計算量が少なく、推論が高速化しやすいので、同じくらいのパフォーマンスなら基本的に次元数は少ないほど良いと思います。↩
-
厳密には low confidence のオブジェクトに対してはカルマンフィルタによる予測とそれに基づく association を行ってます。↩
-
(num_tracklet, num_detection)型の行列であって、tracklet_iとdetection_jが紐づいている時に(i, j)成分が 1 、紐づいていない時に 0 となるような行列。↩