こんにちは、株式会社ACESでインターンをしている篠田 (@shino__c) と申します。普段は博士課程の学生としてNLPの研究をしています。
ここ数ヶ月で ChatGPT に加えて GPT-4 等の大規模言語モデル (LLM) が次々とリリースされていますね。
ChatGPT (gpt-3.5-turbo) はAPIの使用料が安いことから、多くの人が気軽にLLMを使用できるようになり、AI、特にNLPを売りにしている多くの企業は技術的にどうやって競争優位性を築けばいいのか模索しているのではないでしょうか。
その問いに対する1つの答えになりそうなものに、Retriever というものがあります。
例えば、社内にある外部には出せない文書を元に顧客からの質問に答える質問応答のサービスを作りたい場合、ChatGPT のような LLM の訓練にはそのようなデータは使われていないため、prompt として社内にある文書を LLM に与えて質問に答えさせることが必要になります。 (prompt = LLMに与える入力の文字列のこと) 一方で、LLM に与えられる prompt の長さには上限があり、社内にある文書の量が膨大であった場合はそれらを全て prompt に含めることはできません。
そこで、質問に関連する一部の文書だけを検索してきて prompt に追加することが1つの解決策になります。 このように言語モデルの知識を補完するために関連する文書を外部の文書集合から検索してきて言語モデルに入力として与えるような技術を、Retrieval-augmented Language Model (LM) と言います。(新しい Bing AI チャットは Web からの検索で知識を補うようなことをしていますね。参照1,2)
Open AI からも検索に使える embedding という API が公開されており、手軽に検索機能を実装するにはそれで十分かもしれません。(参照)しかし、その API は有料であることに加えて、embedding の訓練に使われたデータとは異なるような特殊なドメインの文書が検索対象で、一般的にメジャーではない語彙が多い場合には Open AI の embedding では検索の精度が劣化してしまう可能性もあります。
公式の Documentation でも、embedding は2020年8月までのデータを用いて訓練されたため、それ以降に起きたイベントについての知識には弱いことが欠点として挙げられています。(参照)
例えば、ACESが提供する "ACES Meet" は "AIがオンライン商談の録画・書き起こしを行い、商談の内容や温度感を共有・解析できる営業支援AIツール"(参照)なのですが、実際に OpenAI の embedding (text-embedding-ada-002)で計算したcos類似度は以下のようでした。
t1 = "AIがオンライン商談の録画・書き起こしを行い、商談の内容や温度感を共有・解析できる営業支援AIツール" t2 = "ACES Meet" t3 = "営業支援のためのAIツールで、オンライン商談の録画と書き起こしを行い、商談内容や感情表現を共有し、分析することができます" # ChatGPT が生成した t1 のパラフレーズ t4 = "りんご" # t1とは全く関係のないテキスト cos(t1, t2) = 0.7234 cos(t1, t3) = 0.9655 cos(t1, t4) = 0.7780
cos類似度 (-1 以上 1 以下) が高いほど似ていると判断されるのですが、この結果によると OpenAI の embedding では、t1 と t3 は似ていると判断された一方で、t1とt2は、t1とt4よりも似ていないと判断されています。
そのため、特定のドメインの文書に特化した検索器 (= Retriever) を独自に訓練することで、その文書を有効に使えるようになり、競合他社との差別化になりうるのではないでしょうか。 直近でも、今年の3月23日に ChatGPT の機能を拡張できる Plugin というものが Open AI から発表されました。(参照) Plugin の1つとして、クエリと関連する文書を独自の文書集合から検索できる ChatGPT Retrieval Plugin (参照)がリリースされており、Githubレポジトリのスターが1万を超えるなど注目が集まっています。 OpenAI の co-founder の Greg Brockman 氏も近い未来に LLM と Retrieval の組み合わせがおそらく主流になるだろうと述べています。(参照) そこでこの記事では検索のために使われる Retriever に関する研究をその訓練方法に着目して少し古いものから最近ものまで代表的と思われるものを紹介しようと思います。 もしも独自の Retriever を訓練する必要がある場合には参考になれば幸いです。 (これまでに多くの論文が発表されており全ては紹介し切れないため、なるべく幅広い訓練方法を紹介するように心がけました。他にも関連する面白い文献や、さらに説明中の言葉遣いや解釈が誤っている箇所がありましたら、こっそり教えていただけると幸いです。)
- Retrieval-augmented LMとは
- Open-domain QA における Retriever の使い方
- Retrieverの訓練方法
- おわりに
- Appendix
Retrieval-augmented LMとは
LM (language model) は自然言語という形での知識は完全に持っていません。 一般に外部の知識源を与えることで、LMが事実ではないことや古くなった情報を生成するのを防いだり、同等の性能を出すために必要なパラメータ数を削減することができます。 Retrieval-augmented LM はそのような手法の一種で、近年も盛んに研究が行われています。 適用可能なタスクは言語生成やOpen-domain QA(下図)、言語モデルの事前学習など多岐にわたります。

Retriever としてはクエリや文書中の各単語の出現頻度を使って類似度を計算するTF-IDFやBM25のようなニューラルネットを使わないスパースな手法が古くから使われてきました。(参照) しかし、ORQA(参照)という手法がニューラルネットを用いてBM25を検索精度で上回るようになってから、ニューラル Retriever の研究が加速したように思われます。 そのため以下では基本的にニューラルネットを用いた Retriever について紹介します。
Open-domain QA における Retriever の使い方
仮に今、Retrieverとしてモデル が得られているとして、質問
に対する回答を出力したい場面を想定します。
また、知識源としての文書の集合が
で与えられるとします。
実際に Retriever を使うときは、まず
のように クエリと各文書をそれぞれ に与えて
次元のベクトル
を得ます。
(ここで、q と d のエンコードには違うモデルを使う場合も同じモデルを使う場合もあります)
その後、クエリのベクトルと各文書のベクトル同士のcos類似度を計算し、cos類似度が大きいものから上位 k 個の文書を検索結果として得ることができます。
その後、それらの文書と質問を入力として、Reader
に回答を予測させます。
この時回答は文書からフレーズとして抜き出すか、0から生成する場合があります。
このように Retriever を使うことで、検索対象の文書集合から質問に関連する文書だけを検索してきて、Reader に与えることで回答を出力することができます。
前提を抑えたところで、次に今までに提案されてきた Retriever の訓練方法を紹介します。
Retrieverの訓練方法
まず質問に対する回答が含まれるような正例の文書がラベルとして与えられている場合に使える教師あり学習の手法を紹介します。 次に、そのようなラベルがなくても学習が可能な教師なし学習についても紹介します。 最後にパラメータを更新しづらいようなLLMと一緒に使う場合の効果的なRetrieverの使用・訓練方法についての最近の研究を紹介します。 教師あり学習をする前に、教師なし学習によって得られた重みで Retriever を初期化することでさらに精度が向上することが報告されているため、色々な訓練方法を知っておくことが重要そうです。
教師あり学習
Dense Passage Retrieval for Open-Domain Question Answering (Karpukhin+ EMNLP2020)
通称 DPR と呼ばれ、元祖ニューラル Retriever という感じです。 質問用のエンコーダと文章用のエンコーダを別々に用意します。 どちらもBERTを使い、[CLS]のembeddingの類似度を検索に使います。 質問と回答のペアは数千〜数万のオーダーで必要です。 Retrieverの訓練には質問に対して positive pasage と negative passage を用意する必要があります。 positive passageがデータセットで提供されていない場合は、単語の出現頻度に基づくニューラルではない検索手法の BM25 で似ていると判断された文書のうち回答を含むものを positive passage として利用しています。
we use the highest-ranked passage from BM25 that contains the answer as the positive passage
BM25と比べて、top-20の検索精度で9-19%の向上が可能です。 Retriever 単体の検索精度は以下の表の通り(DPR が劣る場合もあり)
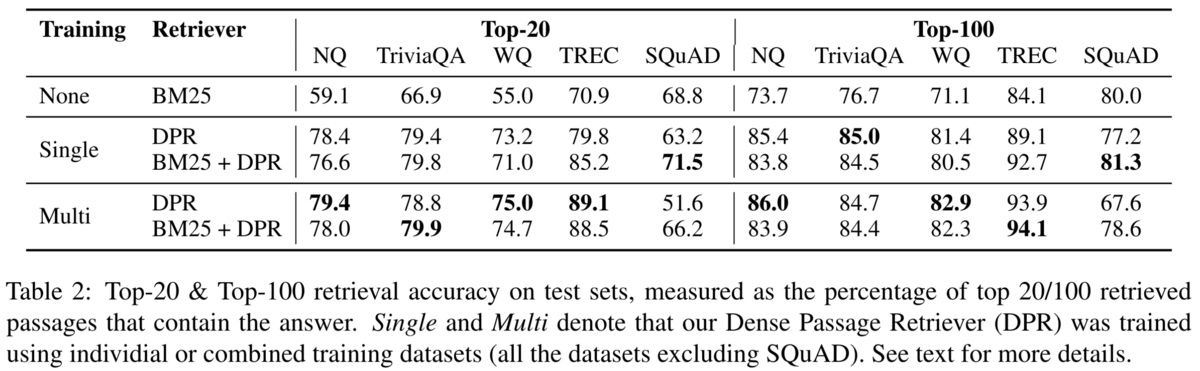
Retriever の研究はこの論文を引用しているものを探せば良さそうです。
教師なし学習
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis+ NeurIPS2020)
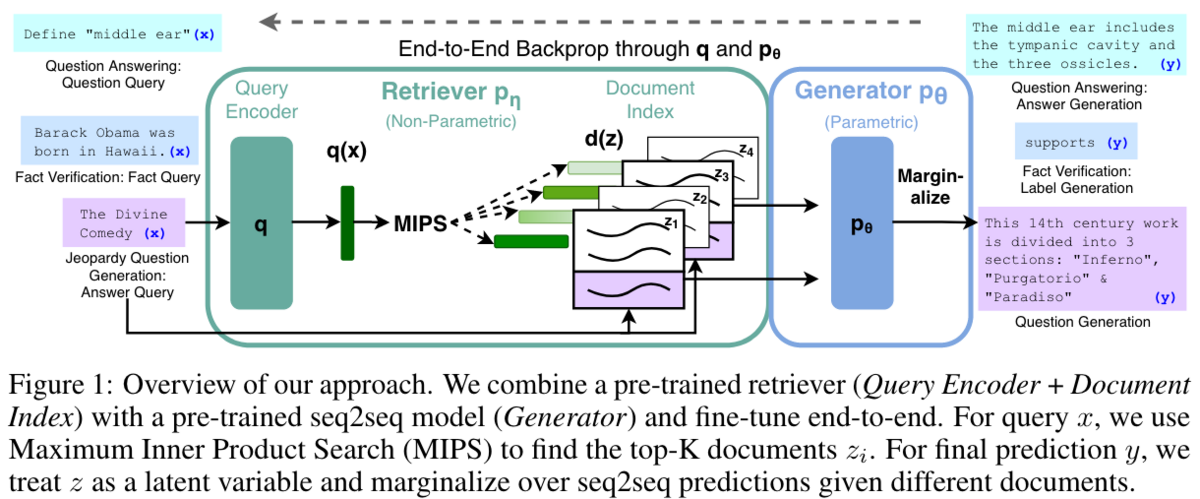
手法名は Retrieval-Augmented Generation (RAG) です。 先程のDPRとは異なり、Retrieverに対するラベルを用意する必要がない教師なし学習を提案しています。 大量の検索対象から関連する文書をラベルとしてアノテーションするのは大変そうですし、BM25で擬似的にラベルを作るのも限界がありそうですよね。
RAG では、検索されてきた関連する文書を潜在変数 z とみなして、クエリ x とラベルyのペアのデータのみで end-to-end に学習しています。つまり、Retriever のラベルを必要としない訓練方法を提案しています。 評価は Open-domain QA に加えて、言語生成や Fact Verification でも行っています。 DPRと同様、クエリと文書には別々のエンコーダを用意しています。 Retriever の初期化には DPR を用いています。 また Retriever を訓練している際に検索対象の文書のベクトルを更新するのはかなりの計算量ですが、これは更新せずに固定しても大して精度は変わらないことを示しています。
Unsupervised dense information retrieval with contrastive learning (Izacard+ Transactions on Machine Learning Research 2022)
対照学習による教師なし Retriever の Contriever というモデルを提案しています。
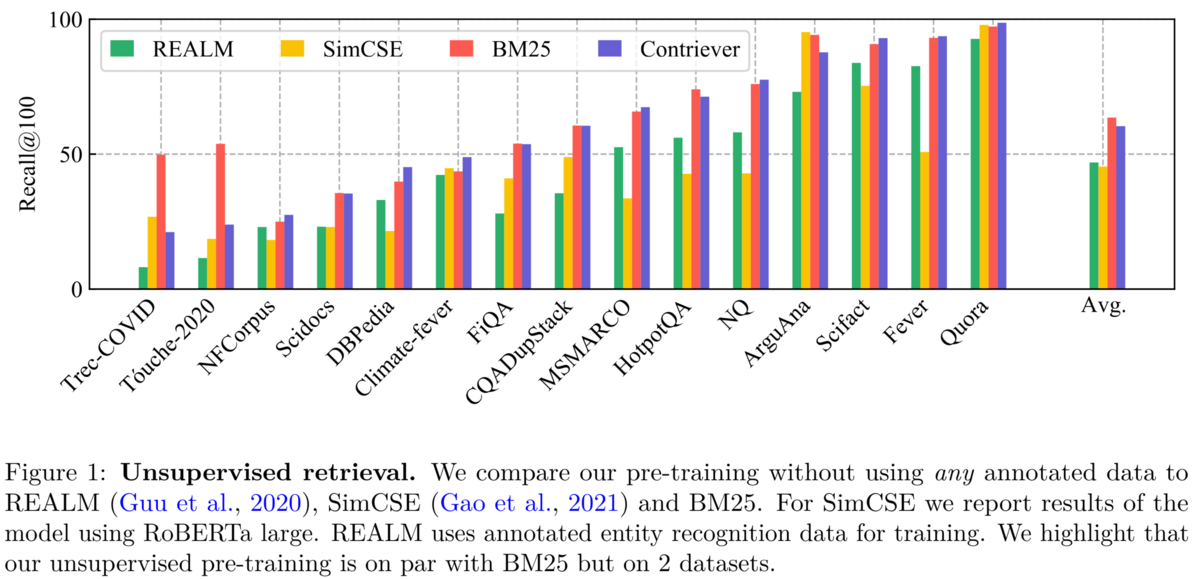
背景として、ニューラル Retriever は訓練データとは異なるドメインのテストセットではあまり性能がよくなく、かえってBM25などのスパースな手法がニューラル Retriever を上回ることがあリました。 例えば上図に示されるように、Trec-COVID という COVID-19 に関する文書からなるテストセットでの検索精度は、BM25の方が他のニューラル Retriever よりも高いです。 この原因について、ニューラル Retriever の訓練には COVID-19 に関する文書が含まれないからだろうと著者は推測しています。 一方、ここで提案されている Contriever は訓練セットがない BEIR ベンチマークで多くの場合BM25を上回っています。 さらにContrieverを初期化に用いて fine-tune することでドメインに特化した Retriever を得ることもできますし、英語データから低リソース言語にも転移できます。
Contriever ではクエリと文書のエンコードには同じモデルを用いています。 DPR は違うモデルを使ってエンコードしていましたが、同じモデルを使った方が新しいドメインに対して頑健であることを示しています。 ベクトルは最終層のmean poolingで得ています。 通常の対照学習と同様に、ここでも1つのpositive documentとK個のnegative documentを用意してクエリのベクトルとのcos類似度をpositive documentとは最大化してnegative documentとは最小化します。
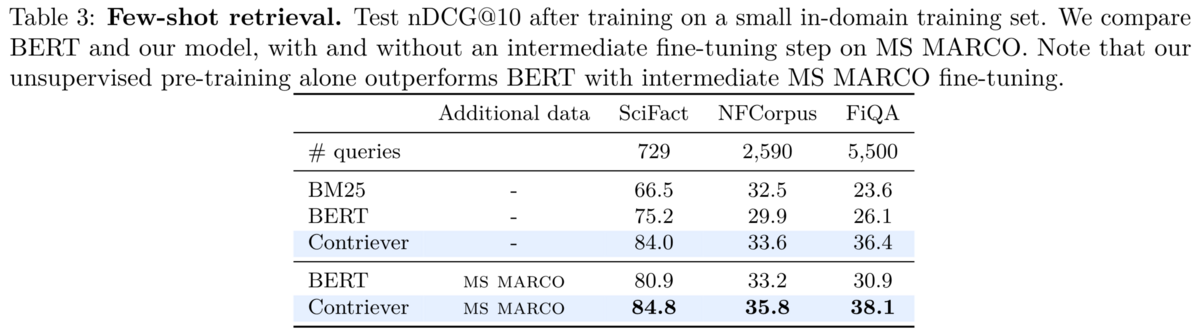
数百〜数千の教師データがある設定では、fine-tuned BERT や BM25 よりも高い精度です。 このことから、Contriever は教師なしでも高い精度が得られるだけでなく、教師あり学習をする前の初期化としても有効であることがわかります。
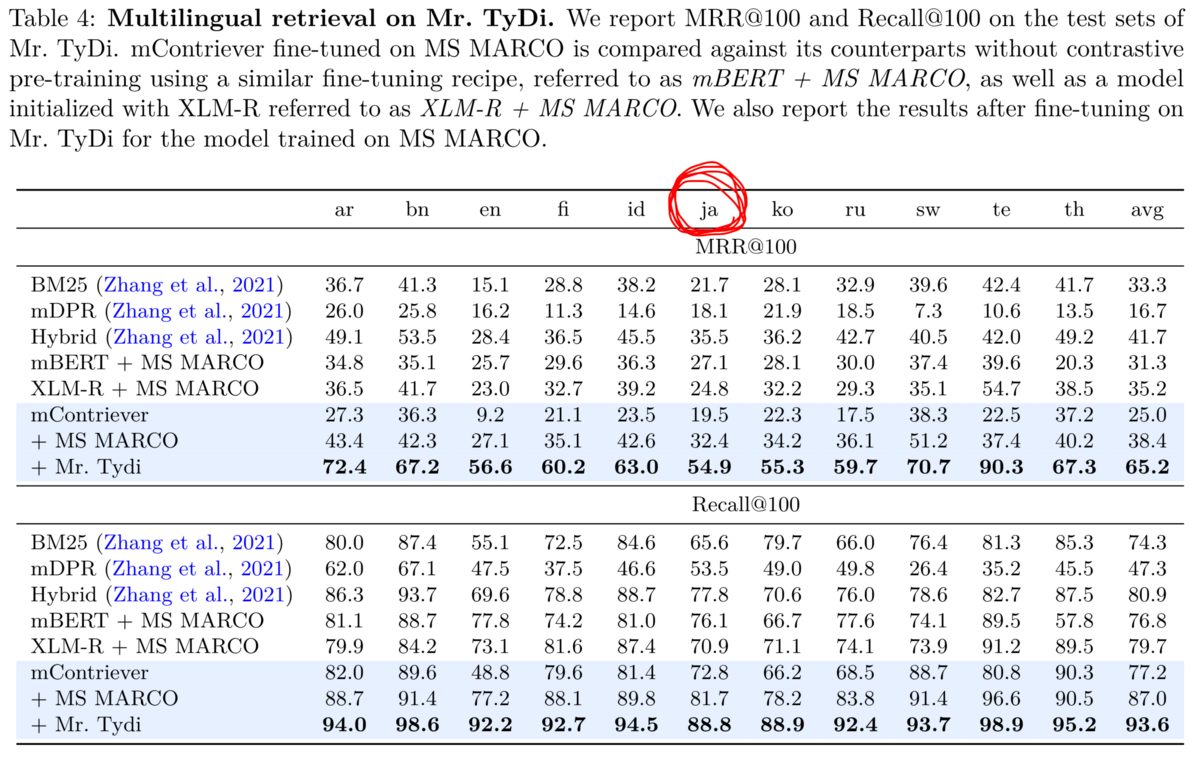
(日本語含む)29の言語のデータで訓練したmContrieverは日本語データ (ja) に対してもある程度汎化可能です。 学習用のコードと学習済みモデルは公開されています。 mContriever を MS MARCO でfine-tuneしたモデルはこちらのレポジトリと以下のコードで簡単に使えます。
from src.contriever import Contriever mcontriever_msmarco = Contriever.from_pretrained("facebook/mcontriever-msmarco")
LLMと一緒にRetrieverを使う
REPLUG: Retrieval-Augmented Black-Box Language Models (Shi+ 2023)
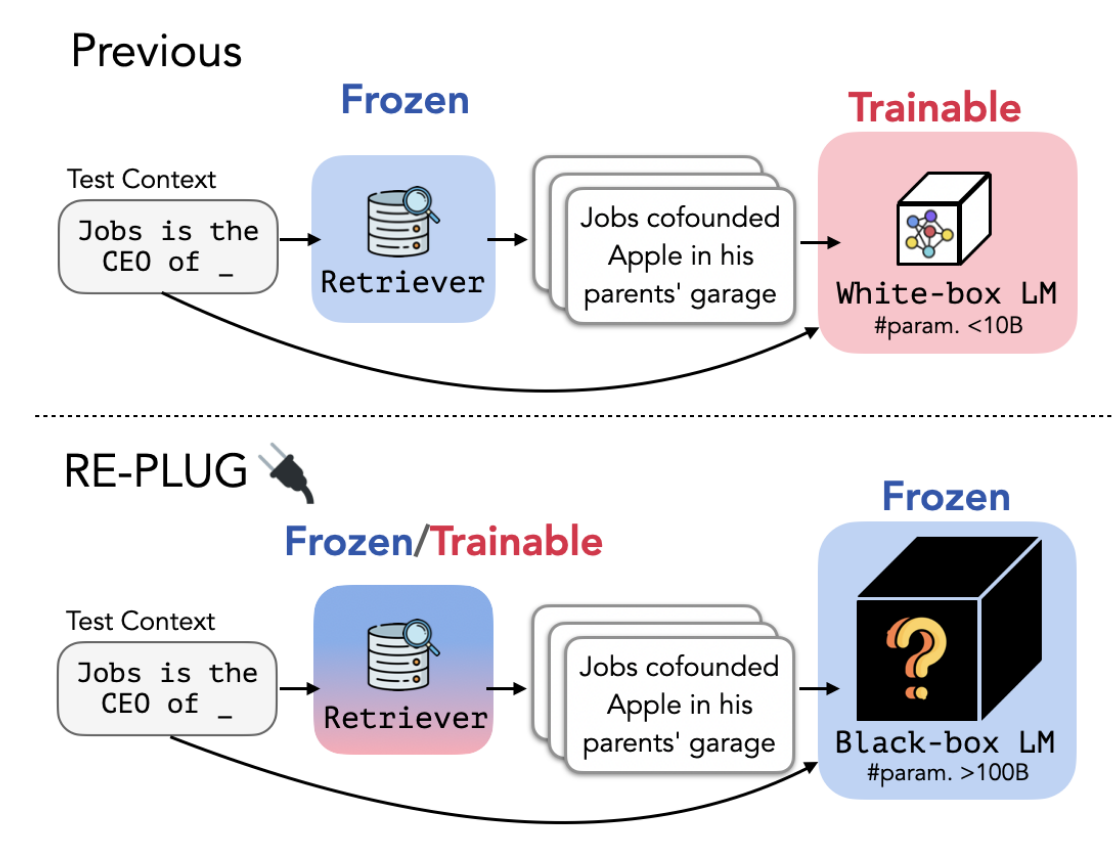
(今までに紹介した Retriever がLLMと一緒に使えないわけではないですが) こちらはLLMを訓練せずに Retriever を効果的に使う方法を初めて提案した論文です。 ここではRetrieverに教師なしモデルを使うのも可能 (Frozen) ですが、ラベル付きデータで訓練してさらに精度を上げることも可能 (Traineble)なことを示しています。
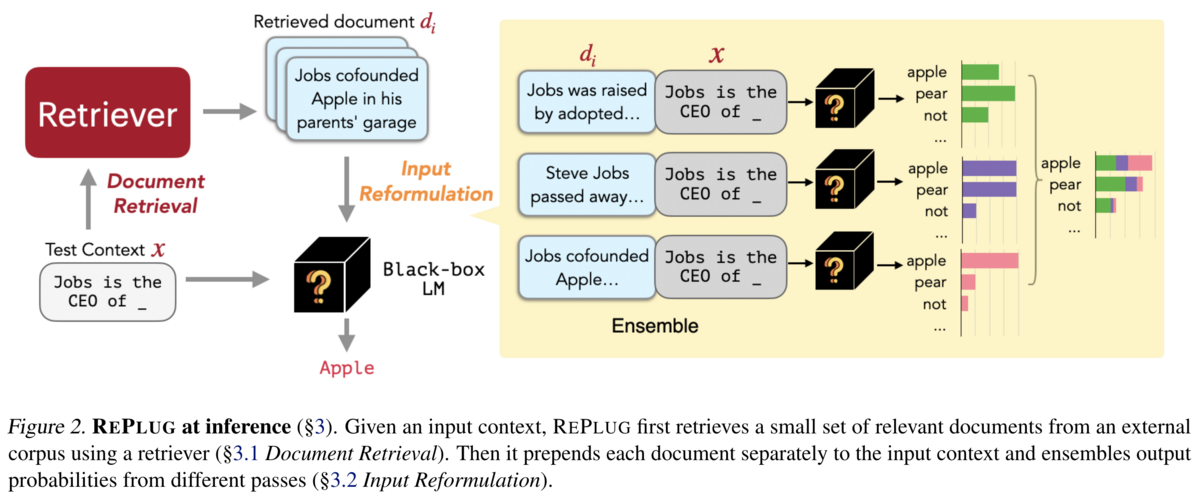
上図の黄色の四角で示されるように、Retrieved document dをそれぞれクエリ x と concat してLLMに入力した後、出力分布を(xとdの類似度で重み付けして)アンサンブルしています。
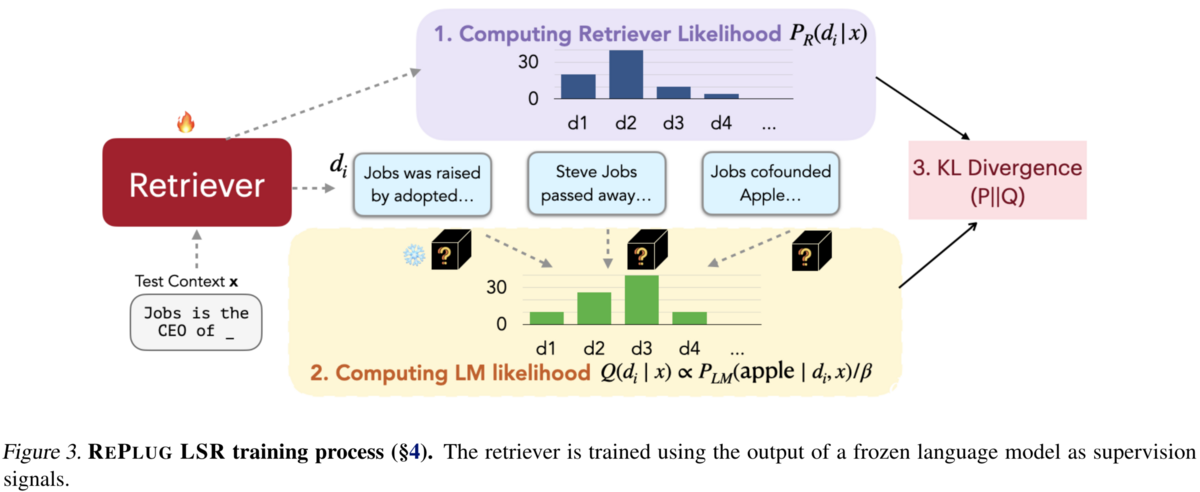
LLMと一緒に使う場合のRetriever の訓練方法
提案手法の1つのRePlug LSRでは、LLMを使ってどの文書を検索するべきかの教師信号をRetrieverに与えて訓練することができます。 大きく以下の4つのステップからなります。
- retrieved documentsにretrieverが与えた確率を計算
- LMを使ってretrieved documents をスコア付け
- 1と2で得られたretrieved documentsの確率分布同士の間のKL divergenceを最小化
- indexの更新
1ではクエリと各文書のベクトルのcos類似度を温度付きsoftmaxにかけます 2では各文書dとクエリxが与えられたもとで正解yにLMが割り当てた確率P(y|d,x)を計算し、これが高ければ高いほどdは良い文書だと仮定します。このP(y|d,x)を各retrieved documentに対して計算した後に温度付きsoftmaxにかけたものを3で使います。 3では1と2で得られたretrieved documentの確率分布同士を近づける。この時にLMは固定でretrieverのパラメータのみ更新する。 4で Retriever の更新に伴うindexの更新はT training steps (実験では3000 step) ごとに行います。
教師なしRetriever (RePlug) にはContriever (Izacard et al., 2022b) を使用し、教師ありの方 (RePlug LSR) の初期化にも Contrieverを使用しています。 LMにはGPT-3 Curieを使用。
訓練データには、Pileというデータから得た800Kの文章を使い、各文章の最初の128 tokenを入力クエリ、後半の128 tokenを正解yとして使用しています。
言語モデル、MMLU、Open-domain QAのタスクでSOTA or パラメータ数のより多いベースラインに匹敵する精度を達成しています。
おわりに
以上紹介した Retriever の研究をまとめてみます。
- 訓練データとは異なるドメインのテストセットでは、検索精度が BM25 > 既存のニューラルRetriever になりうる (Izacard+ Transactions on Machine Learning Research 2022, Figure 1参照)
- Retriever はどうやって訓練する?
- 教師あり学習:質問と文書の正解ラベルで教師あり学習 (Karpukhin+ EMNLP2020) 。正解文書はBM25と質問への回答から人工的に作成することも可能 (Karpukhin+ EMNLP2020)。
- 質問と回答のペアから学習:正解文書を用いずに、文書を潜在変数として扱って質問と回答のペアだけから訓練することもできる (Lewis+ NeurIPS2020) 。ただし質問と回答のペアは教師データとして必要。
- 教師なし学習:対照学習による教師なし学習は有効 (Izacard+ Transactions on Machine Learning Research 2022) で、後発の研究でもfine-tuningをする前の初期化に用いられています。
- LLMと一緒に使いながら訓練:パラメータが固定されているLLMと一緒に使いながら Retriever を効果的に訓練する方法 (Shi+ 2023)。
- エンコードの仕方
- Retriever の初期化
- BERT-base (Karpukhin+ EMNLP2020)
- DPR (Lewis+ NeurIPS2020)
- Contriever (Shi+ 2023)
- などが使われる
場合によってはラベル付きデータセットを用意できる場合と難しい場合、LLMと組み合わせてさらにチューニングしたいなど多くのユースケースを想定して、なるべく広範囲の訓練方法から代表的なものを紹介してみました。 訓練方法としては、教師なし学習ではアノテーションがいらないという利点がある一方で、特定のドメインの文書での検索精度をより上げるためには教師あり学習が有効な傾向があります。コストと精度の兼ね合いで手法を選択する必要がありそうですね。 一方で LLM へ入力できる prompt の長さは長くなっており、検索対象の文書がそこまで大規模でない場合には、Retriever を介さずに全ての文書を入力として扱うこともある程度は可能になっていきそうです。
今回は Retrieval-augmented LM についての論文をいくつかご紹介しました。 ACES では今後 ChatGPT のような LLM を用いたサービスの開発に並行して、今回ご紹介した Retriever などの、LLM のための外部モジュールを積極的に開発していく予定です。 弊社の取り組みに興味を持っていただける方は、ぜひ以下のリンクからご応募いただけると幸いです。
気軽に話だけでも聞いてみたい方は、弊社の開発部署のマネージャーとカジュアル面談もできます。
Appendix
最後に、さらに深掘りたい方のために関連する最近の論文を簡単に紹介します。
- ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction (Santhanam+ NAACL2022)
- クエリと文書内のtokenごとの類似度に基づくクエリと文書のマッチング。BEIRベンチマーク において執筆時点で6位の精度です。
- SGPT: GPT Sentence Embeddings for Semantic Search (Muennighoff 2022)
- GPT のような decoder のみの Transformer の使い方を工夫して Retriever として利用する方法を検証している論文です。BEIRベンチマーク において執筆時点で1位の精度です。
- One embedder, any task: Instruction-finetuned text embeddings (Su+ 2022)
- Atlas: Few-shot Learning with Retrieval Augmented Language Models (Izacard+ 2022)
- Retrieverの教師あり学習で、数十の教師データしかないような Few-shot Learning について有効な学習方法を研究している論文。
- Retrieval-Augmented Multimodal Language Modeling (Yasunaga+ 2022)
- CLIPを使うことでテキストだけでなく画像も検索対象とすることができる Retriever を提案しています。GPT-4がテキストと画像を入力にできることからも、multimodal な Retriever は今後需要が増えそうですね。
- コンテキストの量が質問応答モデルのショートカット推論に与える影響について (秋元+ 2023)
- 今年のNLP2023で発表されていた論文です。open-domain QAで検索対象のコンテキストの量と性能の関係を分析しています。検索対象の文書集合に、質問と関係ない (negative) コンテキストが増えるとQAの性能が低下し、関係ある (positive) コンテキストが少ないと、この傾向が顕著になることを示しています。
- Retrieving and Reading: A Comprehensive Survey on Open-domain Question Answering
- Augmented Language Models: a Survey
- 関連分野のサーベイ論文